论文阅读 NetVLAD-CNN architecture for weakly supervised place recognition
NetVLAD, 2016年的论文了,为啥又翻出来呢?
因为之前公司群里分享了ghostVLAD,好学如我,当然抽空就看了这篇论文啦。
然后顺藤摸瓜,发现其中一个作者Dr Relja Arandjelović还是这篇论文的前身NetVLAD的一作~
哇哦哇哦,于是囫囵个地看完ghostVLAD之后,我又找了NetVLAD来看。
而为了阅读顺序,故先写NetVLAD。
至于ghostVLAD,さあさあ〜〜
诸位阅读时要时刻记得这篇文章是2016年发表的,所以有些trick现在看来不那么tricky了,这个毋庸多作置疑。
1. summary
这篇文章主要围绕的是大规模视觉场景识别问题。就是给一张地标图像,快速准确地识别出这张图像的位置。
据摘要里说,这篇文章主要有3个创新点:
- 为场景识别任务构造出了一个可以直接端到端训练的CNN模型结构,NetVLAD就是该模型的一个layer;
- 构造一个弱监督排序损失(weakly supervised ranking loss)来指导模型的参数更新;
- 效果很好。在两个具有挑战性的数据集上超过了非学习性的和现成的CNN描述子,等等。
总的来说,就是把传统的VLAD算法融合到了CNN模型结构里,然后针对特定的谷歌街景数据集(Google Street View Time Machine)用了弱监督排序损失来训练。
且看下文如何分解。
2. overview
时至今日,一想到场景识别(place recognition),大家应该第一个蹦出来的想法就是做特征比对了吧。
训练一个模型,对于每一张输入的图像$I_i$,得到一个固定长度的向量$f(I_i)$。依此法对所要查询的图像q进行操作,
也得到了q的向量表达$f(q)$,然后依次与数据集进行比对即可。
怎么衡量两个向量相近呢?这篇论文用的是欧氏距离(Euclidean distance)。
3. NetVLAD: A Generalized VLAD layer ($f_{VLAD}$)
大家要时刻记得:这篇论文是2016年发的,时至今日,有些trick现在看来不那么tricky了。
在这篇论文发布之时,大多数图像特征提取的流程是:
- 提取很多局部描述子;
- 以一种无序的方式池化(pool).
而这篇文章受当时大火的神经网络影响,设计实现了一个可端到端训练的CNN网络来达到这个目的。
那么,到底NetVLAD是何方神圣?
关于VLAD,这篇论文的作者引用的是2010年的一篇论文:Aggregating local descriptors into a compact image representation,
有兴趣的看官可以自行前往阅读。
原始的VLAD的公式如下(请原谅我懒得敲公式而用了截图。不过话说回来,能有耐心阅读我这篇博客的人,相信至少也更喜欢读英文原文的公式
而不是我翻译过来的词不达意的公式):

看到公式(1)里,阻碍我们把这个公式变成连续的唯一因素就是$a_k(X_i)$,如果我们能把它也变成连续的,那岂不是妙极?

于是乎,作者说:
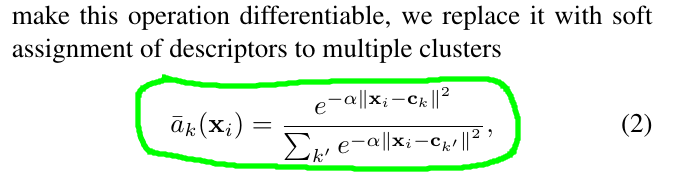
哇哦哇哦哇哦,是不是感觉有那么一丝机智和俏皮?
然后把公式(2)展开,就得到了:

这个就是NetVLAD本尊了。
就这么稍微变换两下, $a_k(X_i)$ 就变成了softmax的形式了。
那么自然公式(4)也就是连续的了,接下来,就是见证奇迹的时刻了,请看CNN如何大展身手:
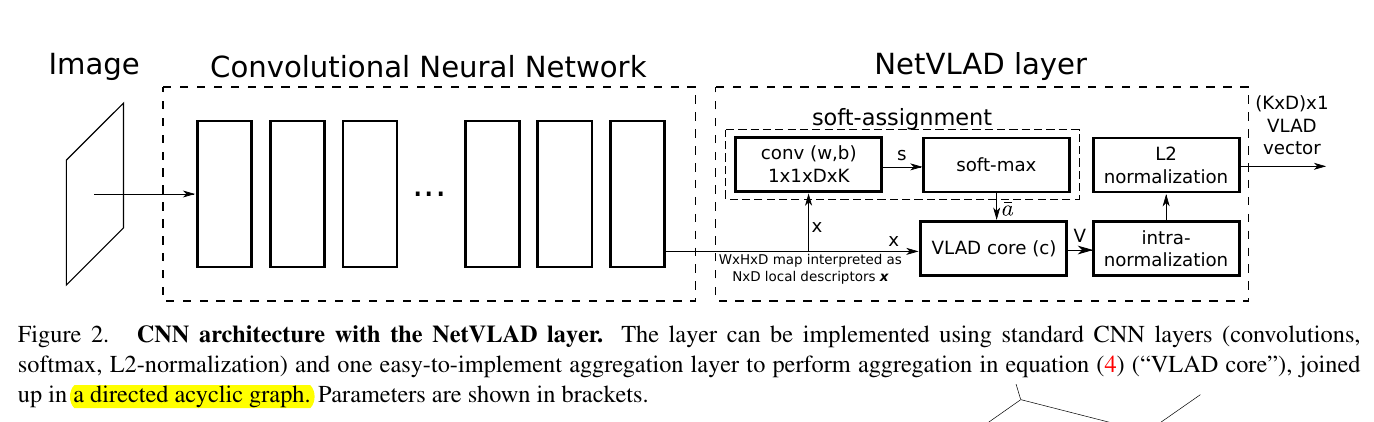
嗯哼,然后这篇论文差不多就说完了。
这节后面的两小节还煞有其事地讨论了一下该方法跟其他方法的区别所在~~
4. Learning from Time Machine data
然后就是摘要里说的弱监督排序损失(weakly supervised ranking loss)。
之所以提出这个损失函数,其实是因为论文所用的数据集是通过谷歌街景(Google Street View Time Machine)获取的,所以没有精确地
标签信息,以及有很大的视角、光照、遮挡、时间变迁而引起的建筑物变化等等因素。几个例子如下:

而弱监督排序损失是怎么操作的呢?
就是对于所获取的街景图像,构造三元组$(q, {p_i^q}, {n_j^q})$作为训练集,$p_i^q$是离 q 的GPS坐标较近的图像集合,
对应的,$n_j^q$就是离 q 较远的图像集合。对于模型来说,应使得每个训练集中,q 与$p_i^q$的最大距离小于 q 与
$n_j^q$的最小距离。其实就是triplet loss的思想,只不过这里用到了谷歌街景数据集上。
然后这个弱监督排序损失为:
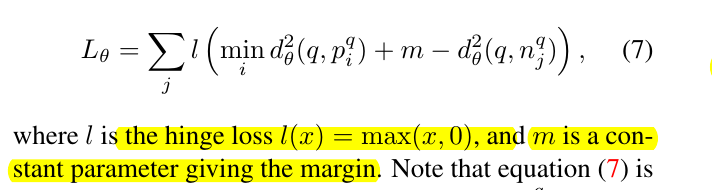
是不是觉得很面熟?
5. Experiments
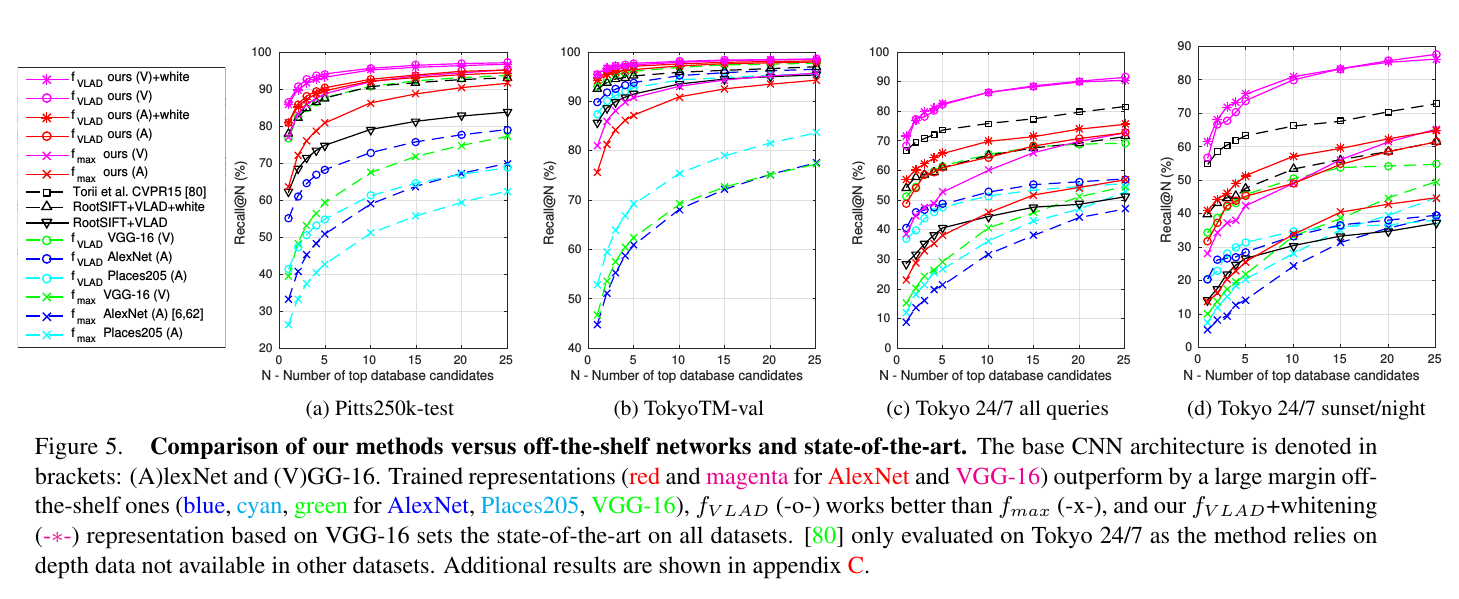
然后就是喜闻乐见的跑数据集测结果的环节了。
这个没啥好说的,无非就是我们测了什么数据集,什么评价标准我们的效果最好,blahblah……
放张图:
6. The end
当然,响应开头,要时刻记得这篇文章是2016年发表的,所以有些trick现在看来不那么tricky了,这个毋庸多作置疑。
也响应开头,看这篇文章主要是其是ghostVLAD的前身,
所以看一看了解了解来龙去脉,多多学习,毕竟我只是个小学生。
致敬作者,完结撒花。
7. The nonsense
说点题外话,搜到了这两篇文章的作者之一Dr Relja Arandjelović的个人主页,说实话有点羡慕。
同时有点感叹。
我在这里费劲巴拉地看人家两年前的文章,然而人家的主页排的是这些:
根本连给这片论文一行的空间都没有……
只能说高山仰止,我不知何时能有个出头之日……
sigh~~
扯远了,况且词不达意,书不尽言,就到这吧。
real ending,完结撒花。

与诸君共勉。
当然我有了ccslience了,不想要受女孩子欢迎~~~
regards.