Interative Learning from Verbal Correction
- paper: Interactive Robot Learning from Verbal Correction
- codes: Olaf: Interactive Robot Learning from Verbal Correction
0. 碎碎念
最近真是想不到,看了几周的机器人相关的交互式学习的论文。。。
唉,索性就写一篇博客,记录一下吧,不然年长日久,
到时又要忘记看的这些论文到底是什么了。
1. 前情提要
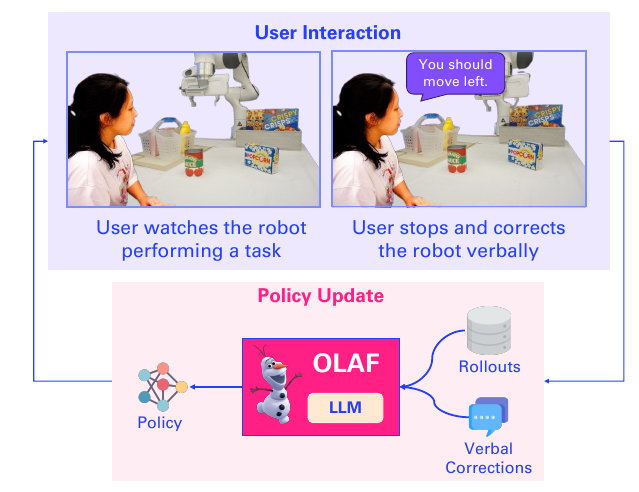
大致思想如上图,总的来说,这篇论文主要有三点:
- User Interaction
- Data Synthesis
- Policy Update
看完这三点,你基本就看完这篇论文了哈哈
2. 庐山真面
开个玩笑,具体来说,论文的大致思想是在机器人执行任务的时候,基于人工纠正的操作来生成训练数据集,
然后生成的数据集加上原有的数据集,
扩充到一起,来重新更新机器人的策略网络的权重,从而达到Interactive Robot Learning from Verbal Correction的目的。
整体一览图如下所示:
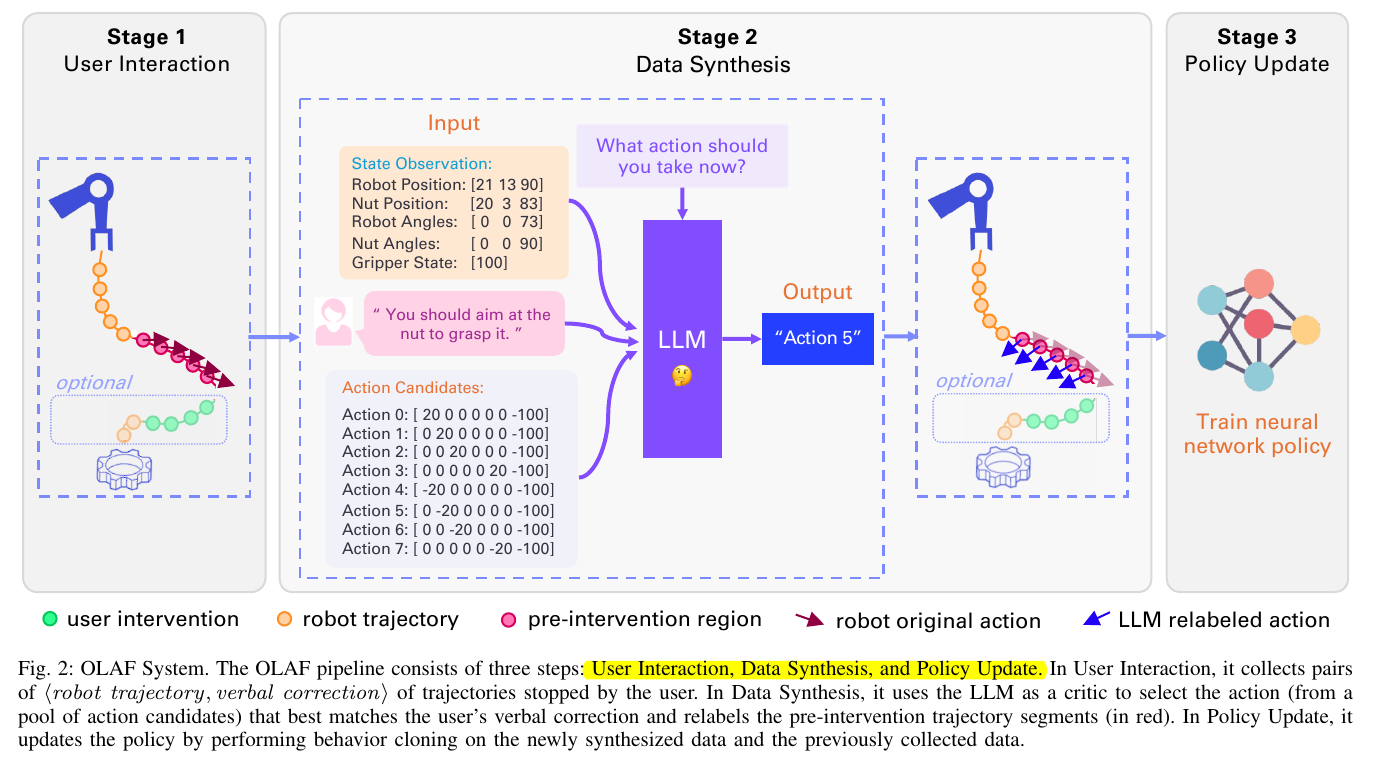
2.1 User Interaction
这一步乏善可陈,就是机器人比如说有个把剪刀放进抽屉的任务要执行,执行工程中可能会出错,人看到出错后,按下停止键并给出指导: 停!要拿剪刀,你要往右靠一点。 这个交互可以执行多次,以便多收集数据以备训练。
2.2 Data Synthesis
根据上一步骤的交互,机器人生成对应的数据集,具体的内容包含4个部分:
1) the robot’s initial trajectory, where the mistakes have not happened;
2) the pre-intervention region, which covers the mistakes;
3) the user correction;
4) the robot’s terminal trajectory after the user corrects the robot and releases back the control;
然后用一个大模型来根据这些数据生成对应的标签,这样你的全新的训练集就有了。
2.3 Policy Update
然后就是训练更新模型了,数据是新生成的加上原有的训练集。
好了,这些就是这篇论文的总体梗概了。
3. show time
然后就是实验结果了,作者说我们用了什么什么数据集,对比了什么什么算法,我们的效果更好,如此而已:

好啦, 现在到了各位看官捧个场的时候啦~~
敬请期待下次更新,完结撒花~~
微信公众号:璇珠杂俎(也可搜索oukohou),提供本站优质非技术博文~~

regards.