StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
- paper: StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
- codes: https://storydiffusion.github.io/
1. 前情提要
两个核心创新点:
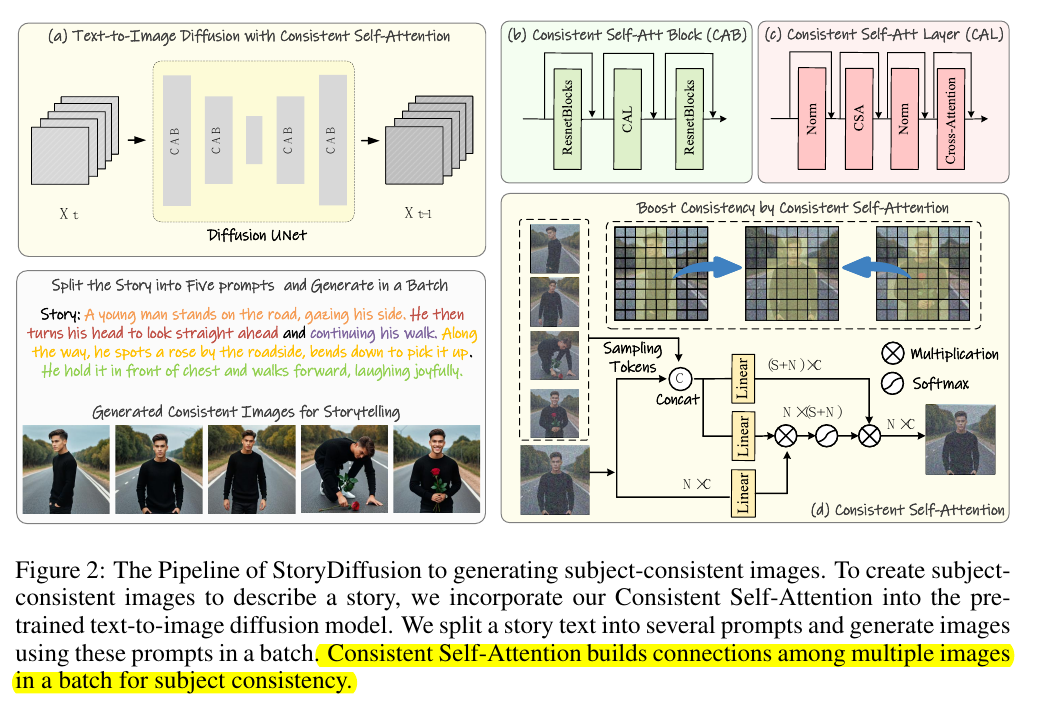
- self-attention模块的 $K$ 和 $V$ 丰富一下,添加上同一batch的其他图片的一些token,就摇身一变成了所谓的
TRAINING-FREE CONSISTENT IMAGES GENERATION了:
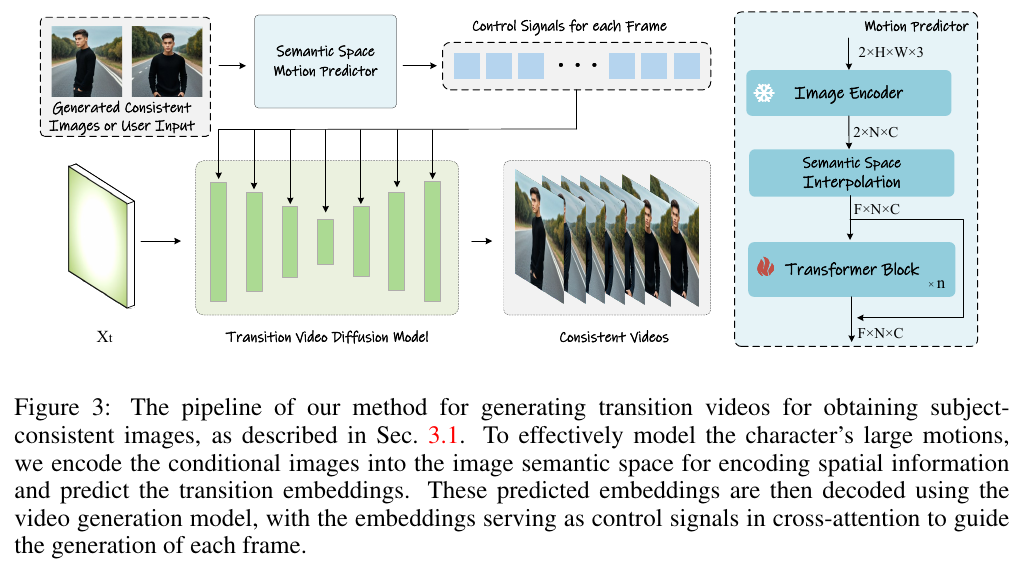
- 把第一步生成的图片序列,拿来插帧。但是不是简单的插帧哦,是先把图encode成embedding,然后用新的8层transformer把两帧扩展到
L帧,作为control signals同样合并到 $K$ 和 $V$ :
是不是已经有点恍然大明白了?那等我再详细介绍下这篇论文的实现细节,我的天,你对这篇论文的理解会有多高,我都不敢想!
2. 拨云见雾
2.1. IMAGES GENERATION
self-attention 大家都很熟悉了,长这样:
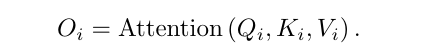
实际推理中,每个图片包含若干个tokens,作者这里说,同一个batch比如包含B帧图片,他针对每帧计算的时候,从所有batch随机采样
一些tokens,这些新采样的tokens和原有的每张图的tokens做一下concat,然后再做注意力计算,那么subject-consistent images 就
成功生成了!

怎么样,是不是感觉你上你也行了?
2.2. VIDEO GENERATION
如果仅仅是上面那些操作,作者可能感觉发paper不够solid,所以又加上了这个视频生成的部分(纯粹是个人不负责任的猜测哈)。
其实也很简单,上面不是生成了图片序列吗,主流的插值做法就是U-Net里加一个temporal module来把二维用奇技淫巧扩展到三维,
也就是所谓的视频了。但是作者这里是不一样的哦,首先是用clip把首尾两帧图片encode成embedding,然后用自己的8层transformer
把两帧图像的embedding扩展到目标的L帧,再把这L帧embedding与原有的文本控制信息做一下concat,然后用来计算cross-attention:
我再把上面的图放过来:
是不是恍然大明白了?
3. show time
然后就是美图秀秀环节了,随便贴一张吧:

更多的动态视频可以去论文的官网尽情欣赏:https://storydiffusion.github.io/
微信公众号:璇珠杂俎(也可搜索oukohou),提供本站优质非技术博文~~

regards.